
The Rise of Open-Source AI: From Hype to Production
Your no-BS guide to building real products with OS models


Hi there 🤗
While everyone is busy discussing the AI battle between China and US, let's focus on what this means for developers and businesses building AI products.
The message is clear - we're entering an era where open-source models are becoming a viable alternative to closed solutions. Data security, independence from big players, and cost-effectiveness are driving this shift. And here's the good news for developers: there's a growing demand for people who can build products with OS models, but not many who know how to do it properly.
Here's what you'll learn in the next 10 minutes:
When you should build your product with open-source models
A practical roadmap to building products with open-source models
Hardware requirements to train and host open-source models
From now on, I'll use "OS models" as a shortcut for open-source models - just so you know ;)
OS vs Closed Models
Let's be honest - most AI-powered applications are just wrappers around GPT models. If your product can be labeled as such, I've got only one thing to say: there's nothing to be ashamed of. I myself have built a few of those and they work great ;)
But it's wise to understand the situation you're in and make an informed decision about next steps. For the rest of you - hopefully I can shed some light on when to choose OS vs Closed models - this is not an easy decision.
To make this issue short and easy to follow, I'll skip the obvious part and won't make comparisons - you can easily google that.
Here is a list of 4 questions to answer that will help you decide between OS vs Closed Models:
Data security - do you have to be 100% sure that external parties won't use your data?
Cost - what are the expected costs for tokens vs infrastructure to host the OS model?
Stability - does your solution need to be stable 99% of the time? What will happen if AI starts to act a bit different (it happens when the model is updated) or when the host of the model shuts down?
Customization - do you need to adapt the model for specific tasks and do you have data for fine-tuning?
Also one bonus and important note about Open-Source:
You don't need as powerful AI as the newest big shot llm from you-know-who. The reality is that you probably need a smaller one that will be trained to get the job done as good (or even better).
Projects with OS Models at Their Core
Let's say you're involved in a project where it has been decided to go with open source models. Congrats! A great journey with exciting challenges lies ahead 😆
The decision to go with OS model(s) adds a new layer of complexity to the project. For some, it's terrifying that such a project can be labeled as "we need to try few things to make sure it's possible". For others, it's a dream comes true 😅
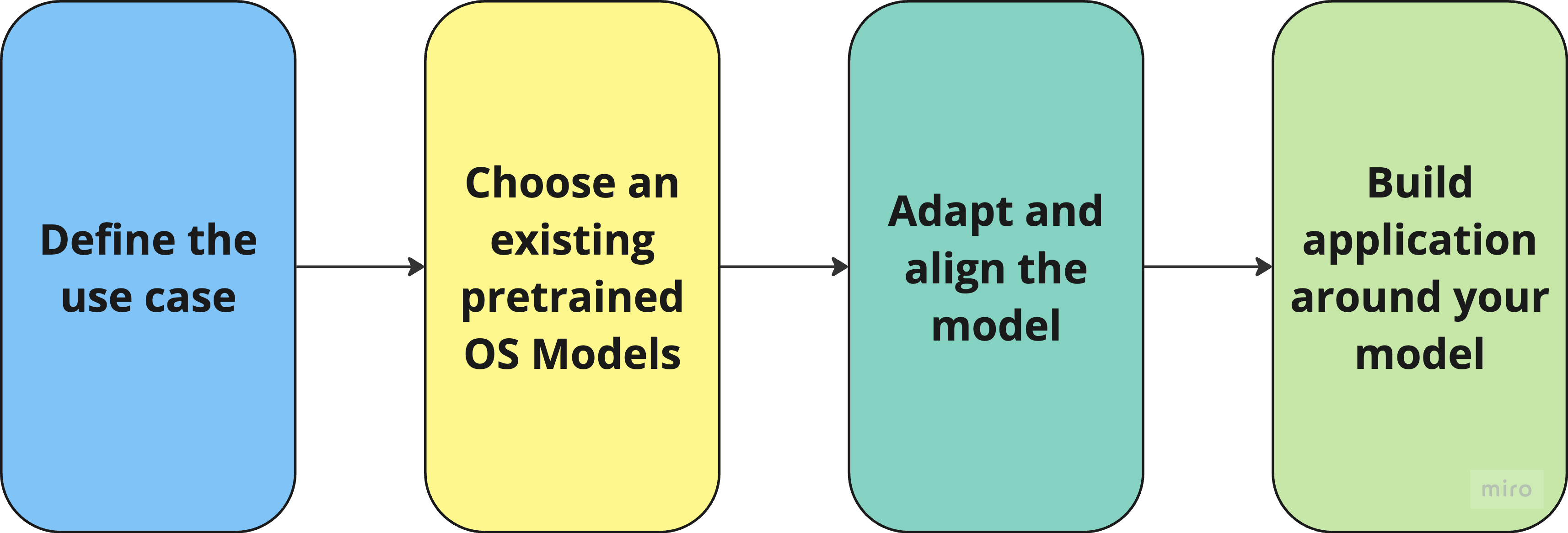
Define the use case
First and most important part is to set clear expectations. You really need to know answers to at least these questions:
What will AI do?
What is the input?
What is the expected output?
How will we measure success?
What should happen when AI fails? (when not if - this is really important)
When you know the answers, then it's time to focus on engineering stuff 👀
Choose and existing pretrained OS Models
In this stage, based on information you collected, your job is to select few most promising models to get the job done. It takes a while. Hugging Face 🤗Hub is a place to scope around.
Adapt and align the model
This is probably the most interesting part. Main goal is to make sure that model will do the job. You’ve got three options:
prompt engineering
fine-tuning
align with human feedback
Start from basics and go deeper only when its needed. For some tasks prompt engineering is enough (few-shot learning solves a lot problems), if not then you need to focus on fine-tuning. This is a topic for a book itself, and the most important is dataset. You need to collect / create data with high quality examples. If you’re not able to, then do not even try it. Last step if where you do reinforcement learning so model answers are more aligned with what you need.
Keep in mind that this step is iterative, you probably won’t get high accuracy on first go.
Build application around model(s)
This is where regular old-school programing has it place - we’re not going to talk about it now. As for integrating model(s) with app you’re building it’s highly recommended to use frameworks like LangGraph. People say that it’s not that hard to implement this things by yourself but why reinvent the wheel?
Seems like a lot, right? You're correct, that's a lot of work to do ;)
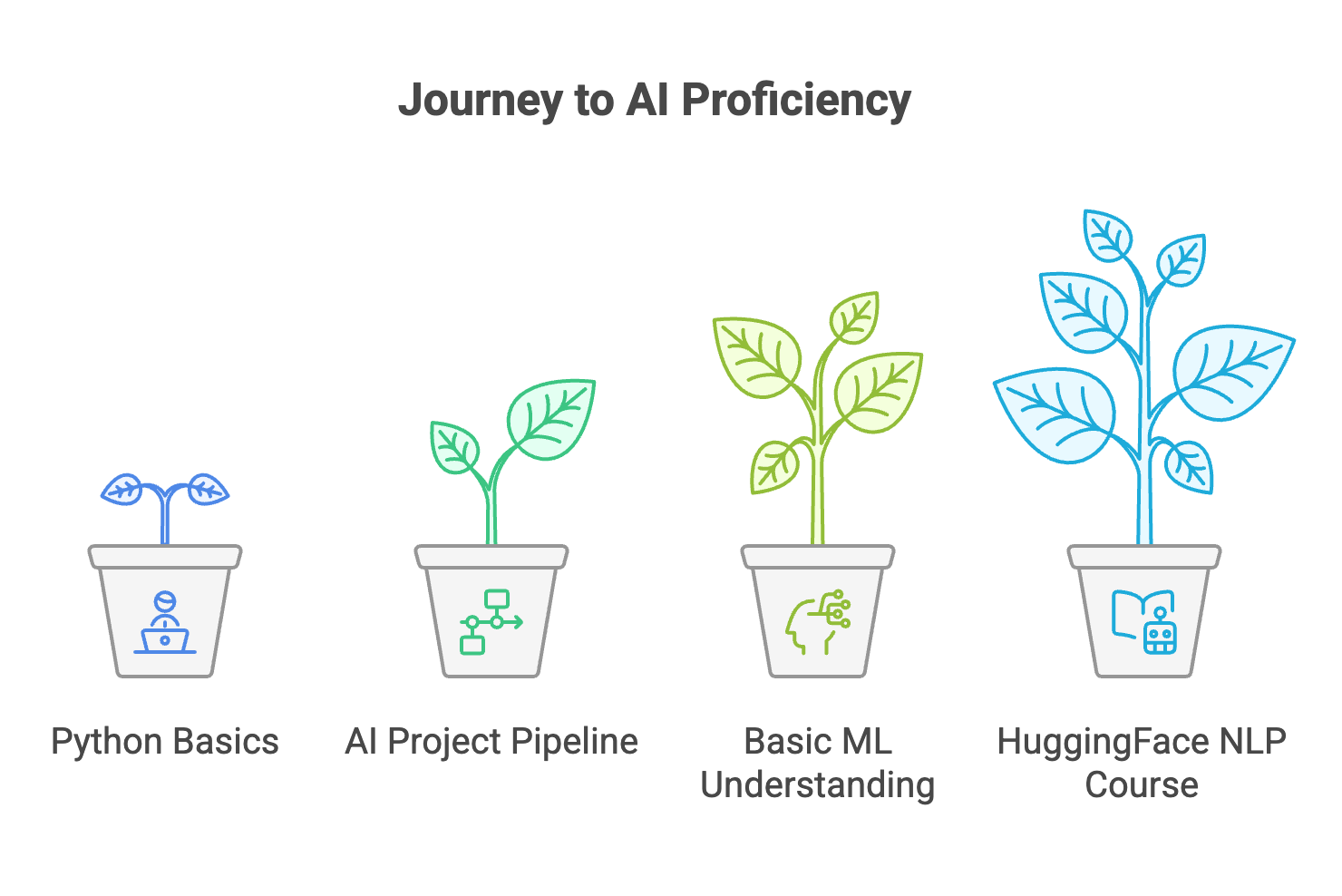
How to Learn, Where to Start
Let's start with one important point: if you're a software developer without any basic knowledge and experience in this field, you're not going to just "figure it out". These topics are complex.
To have at least a chance to make it work, you need to understand the basics and know what questions to ask. Here's a list:
Python basics
AI project pipeline - critical aspects and outcome of each step. Go deeper in what was described in previous section.
Basic ML Understanding
deeplearning.ai machine learning specialization is a good place to start
since I'm mostly involved with LLMs, I recommend going through HuggingFace courses, their NLP course is great ;) focus on transformers and fine-tuning parts
Now you know the basics and where to start. You have enough knowledge to understand where and why you're poking around. From now on, you can start to build simple projects and learn by doing. Also you will know what to learn next without a problem.
Hardware Requirements for Fine-tuning and Hosting LLM Models
Before we wrap up, let's talk about hardware requirements for fine-tuning and hosting LLM models. While going through courses doesn't demand significant resources, production-grade applications require careful consideration of hardware costs. Here's what you need to know:
For Inference (Running the Model):
Basic rule: 4GB+ RAM per 1B parameters
Example: a 7B parameter model needs ~28GB RAM
You can significantly reduce this using quantization (8-bit or 4-bit)
For Fine-tuning:
Full fine-tuning requires approximately 3-5x more memory than inference, depending on batch size and the optimizer
PEFT methods (like LoRA) can reduce this to almost inference-level requirements
Learn more about optimization techniques - thats a game changer and is rapidly changing the landscape of LLM
Training time varies from hours to days depending on dataset size and hardware
Summary
We've covered the practical aspects of working with open-source AI models. Here are the key takeaways:
1. OS vs Closed Models Choice:
Consider security, costs, stability, and customization needs
Smaller, fine-tuned models often outperform larger generic ones
Open-source models are becoming a viable alternative to closed solutions, but closed models are great if you can use them
2. Project Implementation:
Clear expectations and failure handling are crucial
Follow a structured process from model selection to deployment
Don't skip the monitoring phase
3. Learning Path:
Start with Python and ML basics
Focus on practical projects
Use HuggingFace resources for hands-on experience
4. Hardware Planning:
Calculate memory requirements based on model size
Consider optimization techniques for cost reduction
Plan for both inference and fine-tuning needs
Remember: Building with OS models might seem overwhelming at first, but with proper planning and understanding, it's a manageable and often rewarding path. Start small, learn continuously, and scale as needed.
See you in the next issue! 👋
Totally agree about the viability of open-source models! The real game-changer isn't just choosing between open vs. closed - it's understanding when each makes sense for your specific use case.
I've been experimenting with both approaches (and honestly failing quite a bit initially D:), and here's what I've learned: Sometimes a smaller, well-tuned open-source model actually outperforms the 'big names' for specific tasks. Especially when you need precise control over data handling and customization.
The key is being realistic about your resources and needs. Not every project needs the latest cutting-edge model - sometimes the 'boring' solution is the right one :)
Want to see some real experiments with AI tools in action? I write about my successes (and failures!)