
Fine-tuning LLMs: Building a Text Anonymizer in 30 Minutes
A Practical Guide to Training Your First Privacy Model


Hi there! 👋
Last week we explored how to generate high-quality training data for AI models. Today, we're exploring how to use that data to build a basic text anonymization model. While it's not production-ready, it's a perfect starting point for understanding fine-tuning!
Let me show you what we're going to build - and yes, you'll get all the code! 😋:

By the end of this guide, you'll have a working model that can automatically anonymize sensitive information in any text while preserving its structure and meaning. And the best part? It will run locally on your machine! 🚀
In case you missed it - previous issue:

What is Fine-tuning? And Why Should You Care? 🤔
Instead of diving into complex theory, let's focus on what fine-tuning means for your projects. Think of it as teaching a smart student (the model) a very specific skill. Here's the practical breakdown:
Input Processing: Show the model examples (like bank statements with sensitive data)
Prediction: Let it try to anonymize the information
Error Calculation: Check how well it did
Weight Adjustment: Help it improve based on mistakes
Behind the scenes, two main mechanisms make this possible:
Gradient Descent: The model's way of learning from mistakes
Figures out what went wrong
Determines how to fix it
Makes small improvements
Backpropagation: The actual learning process that:
Identifies which parts of the model need adjustment
Calculates the necessary changes
Updates the model's knowledge
💡 Note: The explanation above is a simplification. In reality, backpropagation computes the gradients that are then used by gradient descent to update the model's weights. These processes are tightly integrated and work together as a continuous learning cycle rather than as two entirely separate stages.The best part? We're not starting from scratch - we're taking an already smart model and teaching it a new trick! 🎓
Why Fine-tune? Show Me the Benefits! 🎯
Let's cut to the chase. Here's why you might want to fine-tune a model:
Better Results: While prompt engineering is cool, fine-tuning often wins in specific tasks. Our anonymization model will consistently identify and replace sensitive data without complex prompts.
Cost Efficiency: Instead of paying for expensive GPT-4 API calls, run your own optimized model. Your wallet will thank you! 💰
Data Privacy: Can't use cloud LLMs due to regulations? A fine-tuned local model keeps your data under your control. Perfect for EU companies! 🔒
Specialized Tasks: When you need reliable performance at scale, fine-tuned models are your best friends. They excel at following specific patterns.
Why Do We Need Anonymization? The Real-World Problem We’re Trying To Solve 🔒
Let's talk about the elephant in the room - data privacy. Here's why anonymization is becoming crucial:
Data Privacy: Your users trust you with their sensitive information. Don't let them down!
GDPR Compliance: EU regulations are strict, and fines are hefty. Better safe than sorry! 💸
Data Security: Keep sensitive information secure from unauthorized access. Sleep better at night! 😴
Here's the bigger picture: imagine you want to use ChatGPT or other cloud AI services, but can't share sensitive data with them. What do you do?
The solution: Build an anonymization proxy! It sits between your application and the AI service, ensuring no sensitive data ever leaves your control. Smart, right? 😎
💡 Quick Note: While you could use NER (Named Entity Recognition) models for this, they're limited to predefined labels. We're aiming higher - a more flexible, context-aware solution that can handle any type of sensitive data!
Let's Get Our Hands Dirty! 👨💻
Before we dive into code, let's make sure we understand what we're building. Our goal is to create a model that can:
Handle various document types (emails, chats, forms, etc.)
Identify and replace sensitive information consistently
Run quickly and efficiently on your local machine
Data Preparation: The Foundation of Success 🏗️
You know what they say - garbage in, garbage out! The quality of your fine-tuned model depends heavily on your training data. Here's what you need to nail down:
1. Data Format: We're keeping it simple but effective:
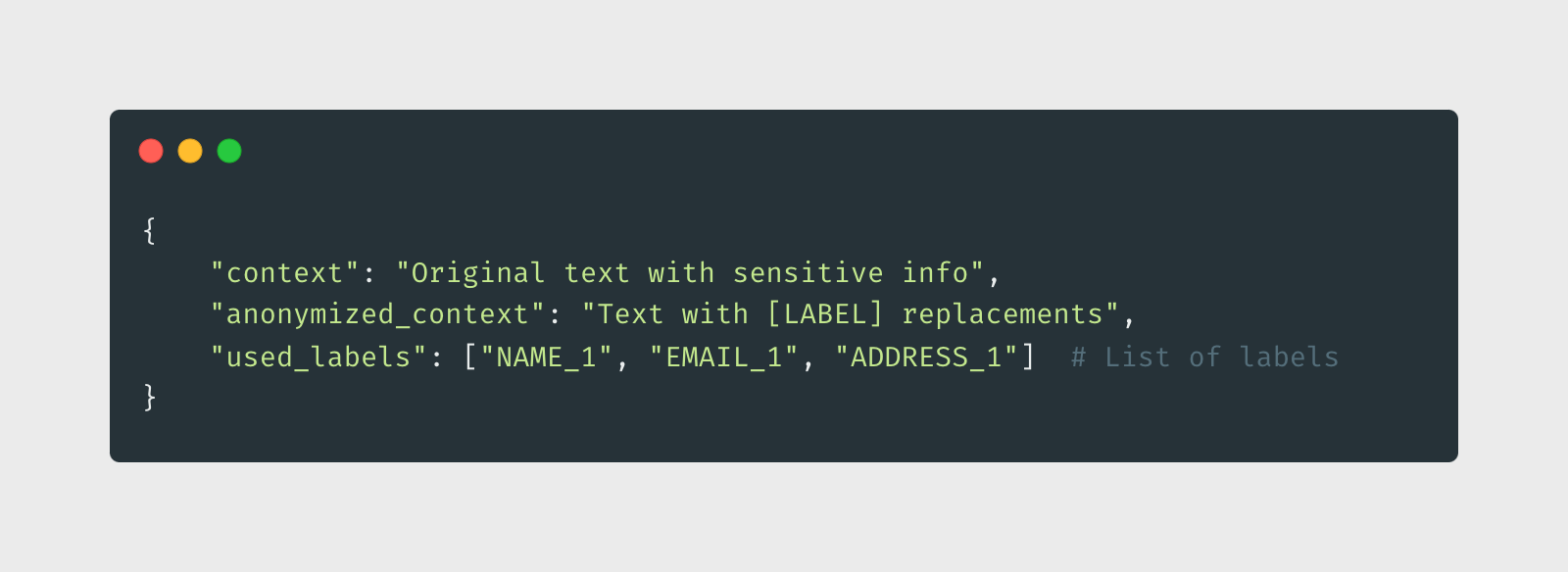
2. Data Distribution: The secret sauce 🌟
Mix different document types (emails, bank statements, medical records)
Include various combinations of sensitive data
Cover different writing styles and formats
Don't forget edge cases!
🚀 We've covered that on previous issue 3. Data Validation: Quality checks are crucial
All sensitive info properly labeled ✓
Consistent label usage ✓
No missing annotations ✓
Text structure preserved ✓
Ready to see it in action? Let's load our prepared dataset from Hugging Face Hub:

Model Setup: Choosing Our Champion 🏆
Time to pick our model! We're going with FLAN-T5-small, and here's why it's perfect for our task:
Architecture:
Sequence-to-sequence model (perfect for text transformation)
Pre-trained on diverse tasks (already smart!)
Instruction-tuned (follows directions well)
Size & Performance:
Only 77M parameters (tiny but mighty!)
Runs on your laptop 💻
Fast inference times ⚡
Why Not Others?
GPT-2: Great, but not ideal for our task
BART: Awesome but too resource-hungry
T5-base: 3x larger, maybe it’s larger than what we need
Let's get our model ready for training:

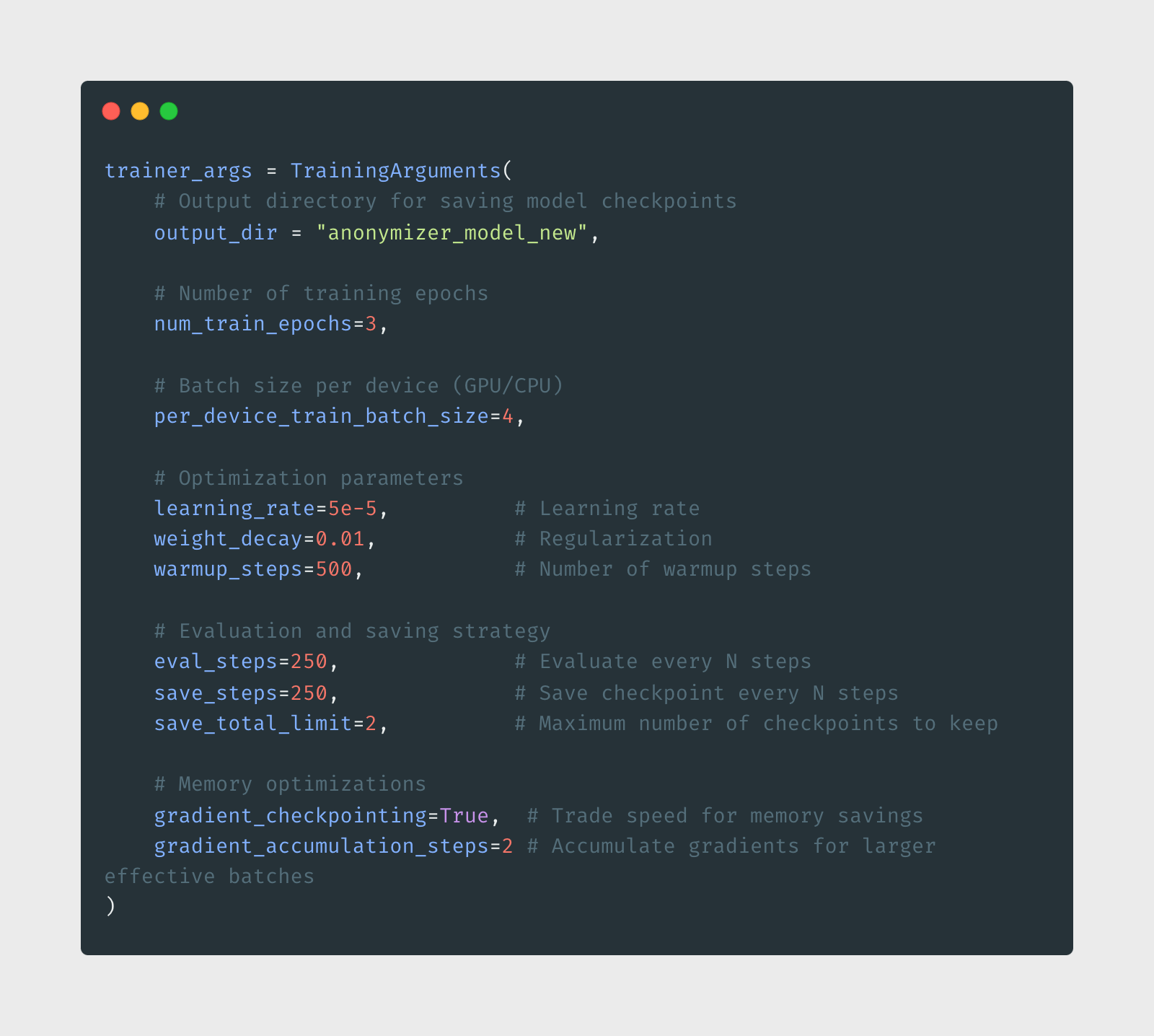
Training Pipeline: The Secret Recipe 🧪
Here's where the magic happens. Let's set up our training configuration:
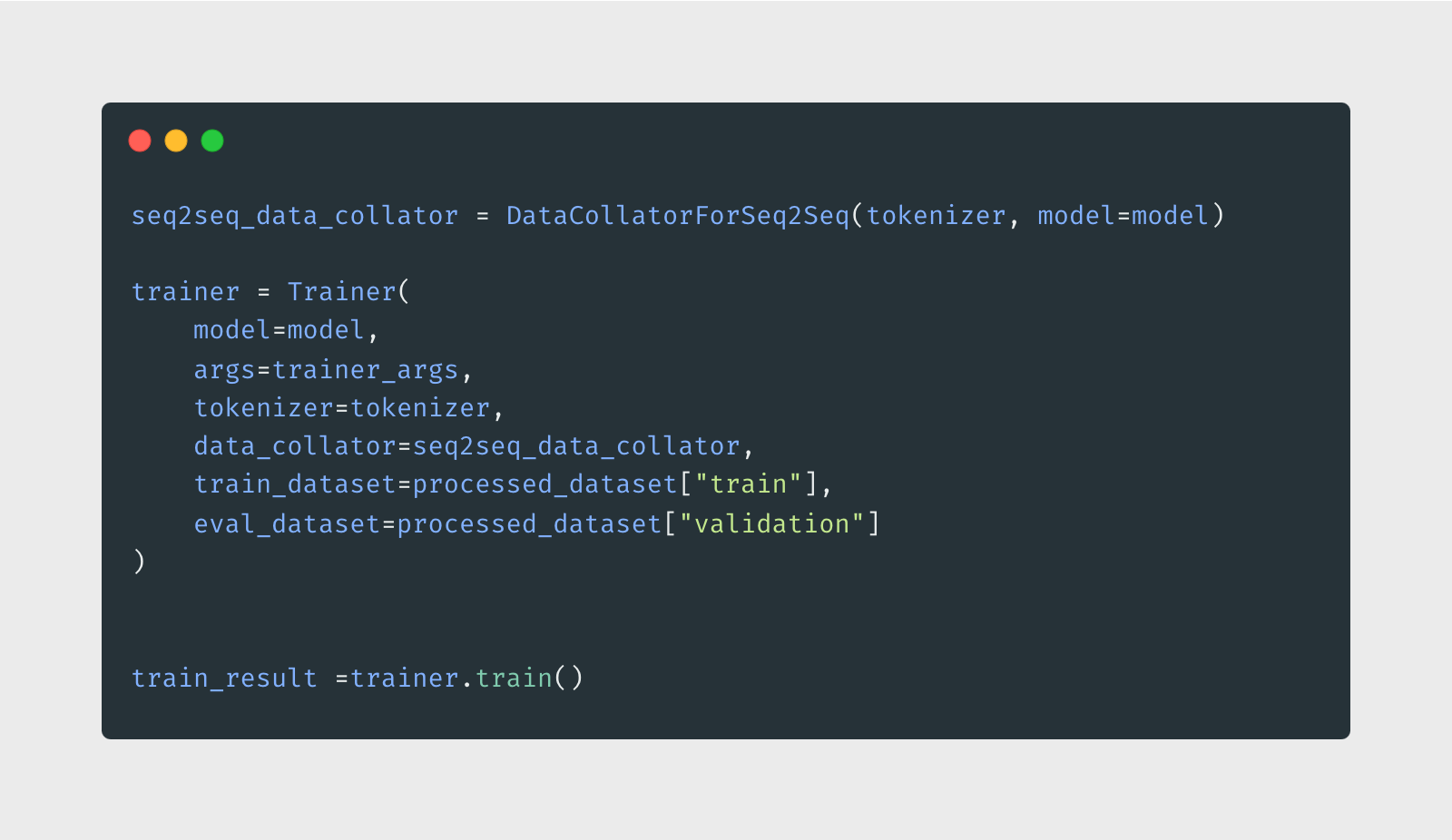
Training Process: Let's Make Some Magic! ✨
Time to train! We'll keep an eye on several metrics to make sure our model is learning properly:
Pro Tips for Success:
Memory Issues? Lower the batch size or use gradient accumulation
Poor Performance? Try adjusting the learning rate or model size or collect more data
Overfitting? Increase dropout or weight decay
Slow Training? Enable mixed precision training (fp16)
Results and Usage: Show Time! 🎭
Time for the demo! 🎬
Note: The model has been trained using a prompt that includes a list of all available labels for anonymization. This approach enables dynamic label specification during inference, making the model more flexible for future use cases. Check repository for details 👀Resources
Want to Learn More? Here's Your Roadmap! 🗺️
🎓 Hugging Face's Fine-tuning Course - this is new supervised fine-tuning tutorial by hugging face
💡 Philipp Schmid's Blog - Fine-tuning wizardry
🚀 TRL Library Documentation- if you’re ready for Reinforcement Learning
Quick Recap: What We've Built 🎯
In this guide, we've created a privacy-first AI solution:
1. Foundation:
Understanding fine-tuning mechanics
Setting up the perfect training environment
Preparing high-quality data
2. Implementation:
Choosing the right model
Configuring training parameters
Monitoring and optimization
3. Best Practices:
Start small, iterate fast
Monitor everything
Test thoroughly
Scale gradually
---
Found this helpful? Share it with your team! 🙌
See you in the next issue! 👋