
Synthetic Data Generation: A Practical Guide & Free Pipeline that easily saves $15,000+
From Theory to Implementation: Building an Synthetic Data Generation Pipeline


Hi there! 👋
Today's issue is a bit more technical - we're diving into synthetic data.
Instead of focusing on "big players needing more data for real AGI", we'll explore why and when regular companies need synthetically generated data.
And as a bonus, you'll get a ready-to-use notebook for generating your own synthetic data 😋🎁
If you missed the latest issues, here are two posts you might find interesting:


What is Synthetic Data and Why Do We Need It? 🤔
In the AI era, data is the foundation of every AI project - whether you're building a new AI-powered application or automating business processes. Even if you're currently focused on closed genAI model integrations, understanding synthetic data concepts might be crucial for your future projects.
The AI model development process can be simplified to these key steps:
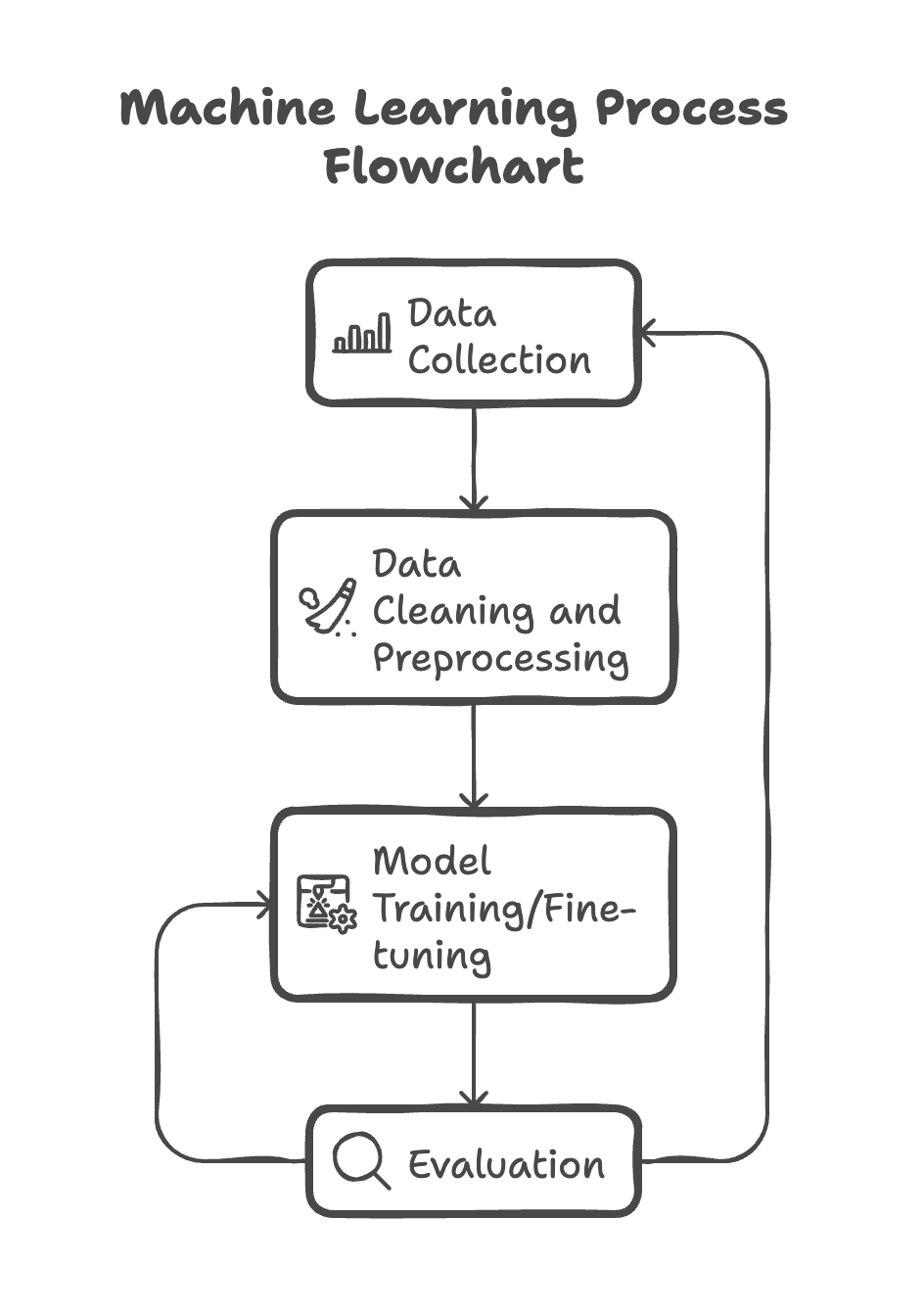
However, reality presents several challenges. Most companies face three major obstacles:
Insufficient amount of data
Poor quality of existing datasets
Privacy concerns and regulatory constraints
If you find yourself in this situation, you have several options:
Manual data creation (time-consuming and expensive)
Purchasing existing datasets (very expensive and often doesn't meet specific requirements)
Synthetic data generation (optimal solution in many cases)
Real-world Example: Distilled Models 🎓
It’s not hard to find example where synthetic data played crucial role in building AI model - DeepSeek distilled models where created this way ;)
Knowledge Distillation is an advanced machine learning technique where a larger model (the "teacher") transfers its knowledge to a smaller model (the "student"). Synthetic data plays a crucial role in this process.
The large model (teacher) generates high-quality synthetic data
The smaller model (student) learns from this data, achieving similar quality with lower computational requirements
This process is iterative and carefully controlled
When Do You Need Synthetic Data? 🎯
You're building your own model (or fine-tuning a pre-trained one)
You find yourself in a situation where you can't obtain enough real-world data
You can collect real data, but it would take too long or be too expensive
How to Do It? 🛠️
First, you need to plan the entire model creation process:
What's the input?
What's the expected output?
What are all possible scenarios?
This is crucial -> you need to show all types of possibilities in your training set.
Let’s generate some synthetic data 👨💻
Proxy anonymizer idea
Let's say you want to build an anonymizing proxy between your application and OpenAI. Why would you want that? In the EU, sharing data with external partners isn't always legally possible (a very common concern). So you might want to build a model that anonymizes all information before sending it to OpenAI that will sit in-between your data and external ai provider.
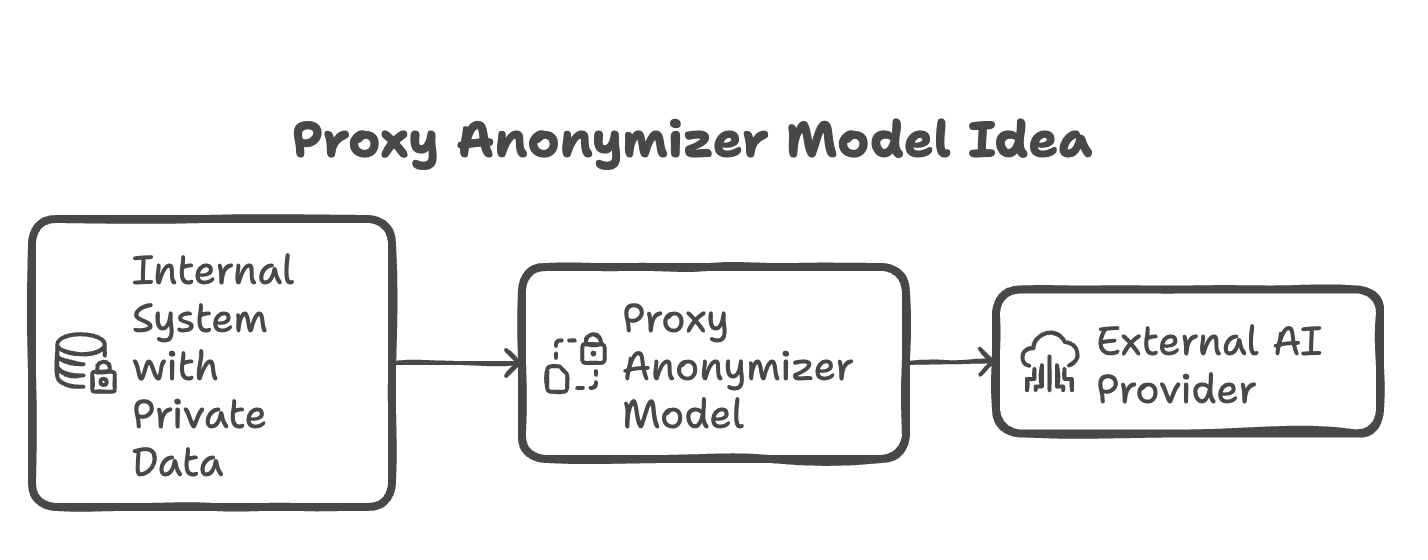
💡 This idea can be done with NER model. However NER models have limitations - they work only on predefined set of labels. If you want to have more generic model you could try sentence to sentence model - this is what we will try to build across few newsletter issues 😇What kind of data you need to train a model
Since we’re building generic sentence to sentence model we will need:
Data from multiple perspectives/sources (emails/chats/JSON objects etc.)
This data in two forms: regular context, anonymized context
Lots of examples, evenly distributed and close to real life examples
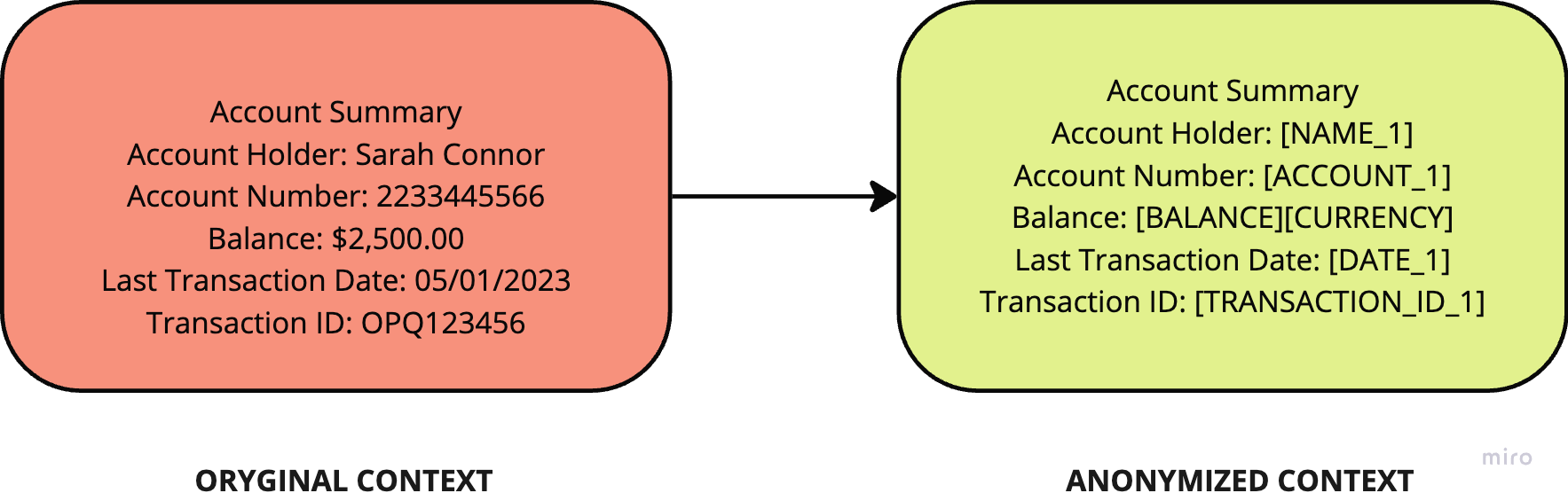
How Much Data Do You Need? 📊
It depends on what kind of AI model you're working on. For LLMs the rule of thumb is:
+/- 5k examples if you want to train a model for a single specific task
Several thousand - if your model will be used for multiple tasks
We’re working on dataset for one specific task. We will aim for 5-10k examples range.
Free Code to generate synthetic data
I've prepared a comprehensive Jupyter notebook that guides you through the process of generating synthetic data. You can find it in this GitHub repository.
Let's break down the key components:
Code explanation
Defining Document Types
We use an Enum to define different types of documents we want to generate. Each document type has it’s own custom prompt for better outcome.
class DocumentType(str, Enum):
"""Supported document types for data generation."""
MEDICAL = "medical"
BANKING = "banking"
BUSINESS = "business"
RECRUITMENT = "recruitment"
SOCIAL_MEDIA = "social_media"
CHAT_PERSONAL = "chat_personal"
CHAT_BUSINESS = "chat_business"
CHAT_SUPPORT = "chat_support"
EMAIL_THREAD = "email_thread"Data Structure with Pydantic and Custom Prompt for each doc type
We use Pydantic to ensure type safety and data validation. Thanks to that we don’t have to work on generated data to structure it for future usage.
class FineTunedDataItem(BaseModel):
context: str
anonymized_context: str
used_labels: str
class FineTunedData(BaseModel):
items: list[FineTunedDataItem]The heart of our system is a function that generates the data. It’s too long to show the code snippet here. Instead, here's just the function description.
async def generate_training_data_async(
document_type: DocumentType,
num_examples: int,
additional_labels: List[str] = None,
temperature: float = 0.3
) -> FineTunedData:
"""
Generate synthetic training data for text anonymization model using OpenAI API.
This function generates realistic examples of documents containing sensitive data, along with their anonymized versions where sensitive data is replaced with tags.
Args:
document_type: Type of documents to generate (medical, banking etc.)
num_examples: Number of examples to generate
additional_labels: Optional list of additional anonymization tags to use
temperature: GPT API temperature parameter for controlling randomness
Returns:
FineTunedData object containing generated examples
Example:
>>> data = await generate_training_data_async(
... DocumentType.BANKING,
... num_examples=5,
... additional_labels=["CURRENCY", "TRANSACTION_ID"]
... )
"""
### rest of the code ###And last step - config expected data use provided scripts to run in optimized way:
# Configuration for synthetic data generation
# This dictionary defines parameters for different document types:
# - First value in tuple: Number of examples to generate
# - Second value in tuple: List of additional labels to include in generation
doc_config = {
DocumentType.MEDICAL: (550, ["DIAGNOSIS", "MEDICATION", "DOCTOR"],
# rest of the config
}
await generate_all_data_async(doc_config)💡 Important aspects:
The generator uses GPT-4o-mini with a low temperature (0.3) for more consistent outputs
We use Pydantic for automatic parsing and validation of GPT responses
The system supports custom tags through additional_labels
All generation is done in parallel for better performance
Document-specific prompts ensure high-quality, relevant examples
The complete notebook with additional utilities for batch processing and parallel generations is available in the repository. Feel free to adapt it to your specific needs! 🎁
💡 Some labels are more common than others - for example, the [NAME] label will be seen as a dominating one. This is what happens in real-life data as well. But be aware that if you're going to use this notebook, you might need to ask AI for specific labels to make the label distribution more even.⚠️ Also! We're asking AI to generate up to 5 examples per request. In my tests, I've seen some instances where it generated fewer examples. Keep this in mind. The number of examples in the config is there for batching - the real output might be slightly different due to AI model unpredictability (but not by much).ROI - Is It Worth It? 💰
1. Manual Data Creation:
5000 examples × 10 minutes/example = 833.33 hours of work
At $20/hour = $16,666.67
2. Synthetic Generation:
API costs ≈ $0 (with current gpt-4o-mini costs being negligible for this dataset size) 🫶
Developer setup time (10h) = $500 (10h × $50/h)
Validation (20% examples manually, assuming 50% of creation time):
1000 examples (20% of 5000) × 5 minutes/example = 83.33h
83.33h × $20/h = ~$1,666
TOTAL: $1,866.67
Savings: $14,800! 🎉
Time to generate 5k examples? 3min 🚀
Potential Problems with Synthetic Data 🚧
Uneven Distribution
While it's relatively easy to generate synthetic data with LLMs, you need to check if the data covers all aspects you need
Solution: Adjust prompts and generate data with specific perspectives / values that you’re missing
Bias
If you use biased models to generate data, that bias might transfer to your target model
Solution: Use different models for generation and thoroughly validate results
Quality and Realism
Data quality assessment isn't easy; output and model performance will tell you a lot about data quality
Synthetic data might not always perfectly reflect real-world data complexity
Solution: evaluate generated data with both statistical approach and by hand
Summary 🎯
Synthetic data isn't just a tool for "big players". It's often the only realistic option for smaller companies that:
Don't have access to large datasets
Have limited budgets
Need to start an AI project quickly
---
If you enjoyed this newsletter, share it with your friends!
See you next time! 👋